It’s been almost two years since Microsoft CEO Satya Nadella made the prediction AI will replace knowledge work — White-collar jobs held by lawyers, investment bankers, librarians, accountants, IT and others.
But despite the huge advances made by foundational models, the shift to knowledge work has been slow. Models have mastered deep research and agentic planning, but for whatever reason, most white-collar jobs are relatively unaffected.
It’s one of AI’s biggest mysteries — and thanks to new research from training-data giant Marker, we’re finally getting some answers.
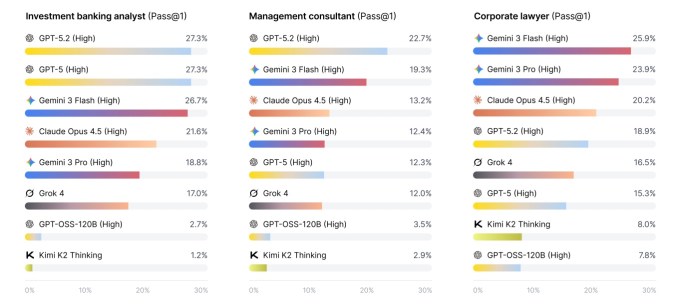
New research shows how leading AI models hold up to real white-collar work tasks drawn from consulting, investment banking and law. The result is called a new benchmark Apex-Agent – And so far, every AI lab is getting a failing grade. Faced with questions from real professionals, even the best models struggled to get correct answers to more than a quarter of the questions. Most of the time, the model came back with an incorrect answer or no answer at all.
According to researcher Brendan Foody, who worked on the paper, the models’ biggest stumbling block was tracking information across multiple domains — something that is integral to most cognitive tasks performed by humans.
“One of the big changes in this benchmark is that we’ve built a complete environment, modeled after real professional services,” Foody told TechCrunch. In real life, you’re working across Slack and Google Drive and all these other tools.” For many agentic AI models, this kind of multi-domain logic is still hit or miss.

The scenarios were taken from real professionals in the specialist marketplace of all markers, who both formulated the questions and set the standards for a successful response. Looking through the questions, which Hug face posted publiclyShows how complex tasks can be.
TechCrunch event
San Francisco
|
October 13-15, 2026
A question in the “Law” section reads:
During the first 48 minutes of the EU production outage, Northstar’s engineering team exported one or two bundled sets of EU production event logs containing personal data to a US analytics vendor… Under Northstar’s own policy, could it consider the export of one or two logs to be Article 49 compliant?
The correct answer is yes, but getting there requires an in-depth assessment of the company’s own policies as well as relevant EU privacy laws
It can also stump a well-known person, but researchers are trying to model the work done by professionals in the field. If an LLM can reliably answer these questions, it can effectively replace many lawyers working today. “I think it’s probably the most important thing in the economy,” Foody told TechCrunch “The benchmark reflects the actual work these people do.”
Attempts to measure professional competence with OpenAI Its GDPVal benchmark — but the Apex Agent test is different in important ways. Whereas GDPVal tests general knowledge across a broad range of occupations, the Apex Agent benchmark measures a system’s ability to perform persistent tasks in a narrow set of high-value occupations. The result is more difficult to model, but more closely tied to whether these tasks can be automated.
While none of the models proved ready to take over as investment bankers, some were clearly close to the mark. The Gemini 3 Flash performed best of the group with 24% one-shot accuracy, closely followed by the GPT-5.2 with 23%. Below that, the Opus 4.5, Gemini 3 Pro and GPT-5 all scored around 18%.
While early results are underwhelming, the AI field has a history of blowing through challenging benchmarks. Now that the Apex test is public, it’s an open challenge to AI labs who believe they can do better — something Foodie fully expects in the coming months.
“It’s progressing really fast,” he told TechCrunch. “Now it’s fair to say it’s like an intern who gets it a quarter of the time, but last year it was an intern who gets it five or ten percent on time. That kind of year-on-year improvement can have such a quick impact.”
]